
O que são?
Sistemas de recomendação são algoritmos que recomendam algum tipo de conteúdo similar com aquele que o usuário consumiu ou simplesmente teve alguma interação como visualização, clique, adicionou ao carrinho, curtida etc.
Onde são usados?
Muitos dos serviços que usamos atualmente possuem algum tipo de algoritmo de recomendação como Facebook e Instagram recomendando postagens e perfis, Amazon recomendando produtos e claro, Youtube recomenda videos e o mais clássico exemplo, Netflix, recomenda filmes.
Pode ser aplicado a praticamente qualquer tipo de conteúdo como músicas, games, livros, cursos, notícias etc. Tudo depende do problema de negócio a ser resolvido, mas em geral, aumentar as vendas, engajamento, manter a atenção do usuário são os objetivos mais comuns. Não vou entrar no mérito do social dilemma, pois não é o objetivo desse post.
Qual a utilidade prática?
Quando o volume de dados aumentou brutalmente ficou difícil fazer escolhas. Imagina se o seu feed do Instagram te apresentasse todas as postagens, mesmo as que não são do seu interesse. O modelo de negócios dele não funcionaria e você, provavelmente não passaria tanto tempo na plataforma.
Com uma forma de filtrar os dados tudo fica muito mais prático. Em vez de passar horas rolando a lista de filmes da Netflix (embora alguns gostem de fazê-lo rsrs), o sistema tenta escolher o melhor filme para manter o usuário entretido, e sabemos que ele acerta muito bem nossas preferências.
Quais as abordagens para recomendar itens?
Há diversas abordagens para se recomendar um item. Claro, cada item tem suas próprias características, portanto deve ser feito um planejamento para escolher a melhor solução.
Pra recomendar um filme, por exemplo, não seria muito eficiente usar a mesma abordagem usada para recomendar um produto num ecommerce.
Vejamos algumas dessas abordagens e suas aplicações de forma resumida:
1ª Query SQL
A primeira abordagem e mais óbvia seria fazer uma query. Mas para isso teríamos que ter uma tabela com as palavras-chave e outra com as chaves estrangeiras do usuário e da palavra-chave, assim se o usuário viu um filme cujo tema principal fosse robôs, por exemplo, o sistema recomendaria outros similares. Mas essa abordagem tem uma série de problemas e limitações, vejamos:
1. Teria que ter alguém ou um algoritmo para salvar as palavras-chave, totalmente inviável.
2. A gigantesca quantidade de palavras ocuparia muito espaço em disco e tornaria as consultas lentas.
3. Ficaria complicado para o sistema aprender as preferências do usuário.
4. O sistema teria que ter uma filtragem para não recomendar um item absurdo, como por exemplo, a palavra bebida pode se referir a bebida alcólica ou a água, logo teria que ter outros critérios para evitar as ambiguidades da linguagem.
5. Talvez o pior, ter que fazer transações para cada usuário a cada login, inviável.
2ª Filtragem de conteúdo
Simplesmente recomenda baseado no conteúdo consumido: visualização, clique, curtida, pesquisa etc. Exemplo: O usuário pesquisou Smartphone Samsung Galaxy A20s, o sistema poderia recomendar outros produtos que contém a palavra Galaxy, por exemplo. Nada de muito inteligente né? Mas melhor que nada.
O grande problema dessa abordagem é que o usuário ficará dentro de uma bolha, sempre recebendo recomendações estritamente similares.
3ª Filtragem colaborativa baseada em avaliações
Essa foi utilizada pela Netflix e ainda é utilizada por muitos serviços até hoje como a Udemy na recomendação de cursos.
Aqui a coisa já começa ficar interessante. Consiste em tentar prever uma nota que um usuário daria para um item usando os dados de outros usuários com gostos semellhantes e assim decidir se recomendaria o item ou não. Veja a representação na figura:
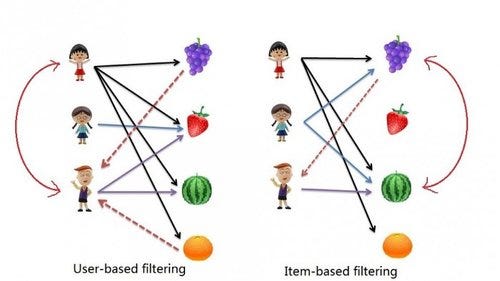
Veja que cada pessoa gosta de determinadas frutas. Na figura da esquerda comparamos os usuários e na direita comparamos os itens.
Veja que a primeira pessoa gosta de todas as frutas e a terceira gosta de morango e melancia, a do meio gosta só de morango. O 1º é muito mais semelhante ao 3º, logo o sistema recomenda uva e laranja para o terceiro, simples assim. Do lado direito o processo é o mesmo, porém o sistema compara os itens que a galera mais gosta, veja que a uva é preferida de 2 pessoas, morango, 0, melancia, todos gostam, laranja, 1 apenas. Quem ganhou foi a uva que vai ser recomendada para o usuário 3.
Agora veja o mesmo exemplo com filmes.
Se o usuário Ana deu 5 estrelas para o filme De volta para o futuro e o usuário João também deu 5 estrelas, os dois parecem ter as mesmas preferências. Mas um item apenas não é suficiente para o sistema sugerir recomendações precisas.
A ideia dessa abordagem é procurar pessoas que possuem perfis semelhantes, como se fossem amigos, que geralmente gostam das mesmas coisas.
Mas o fato de uma pessoa ter visto um filme de comédia uma vez e ter gostado dele não quer dizer que é o gênero favorito dela. Logo precisamos de mais dados para recomendar o item certo.
Assim o algoritmo pode realizar o cálculo da similaridade entre vários usuários e entre vários itens e chegar a números muito mais próximos da realidade.
Dentre as diversas vantagens dessa abordagem estão:
1. Mais rápido, visto que o sistema pode salvar a lista com as notas em períodos determinados e ser consultada apenas quando necessário.
2. Mais eficiente por não ser necessário salvar todas as recomendações no banco de dados.
3. Mais inteligente, pois quanto mais itens são adicionados, novos usuários cadastrados e interação dos usuários com os itens acontece, o sistema obtém melhores resultados.
O problema é que o usuário tem que dar nota e nem sempre eles dão. Aí vem a próxima abordagem.
4ª Deep Learning
Aqui a coisa fica mais profunda. Através de Algoritmos de aprendizagem, você simplesmente passa os dados e o sistema “se vira” para encontrar o melhor modelo para recomendar. Claro, é mais complexo para construir, logo tem que ser avaliada a necessidade do negócio e custos de se usar tal abordagem. Os parâmetros precisam estar bem ajustados e é necessária uma boa base de dados.
A grande vantagem dessa abordagem é que com dados gerados naturalmente já é possível obter ótimos resultados. Veja a tabela de exemplo:

A tabela é apenas um simples exemplo para você entender melhor o conceito, na prática os dados não são armazenados assim.
Suponhamos que o filme Star Wars foi visto por 1000 pessoas e curtido por 90% delas, sendo o que foi mais visto e mais curtido. A probabilidade de o sistema recomendar esse filme para um usuário que viu um filme similar é alta. Tome como exemplo os Youtubers, que pedem curtidas em todos os vídeos. Assim o algoritmo aumenta a relevância do vídeos e entrega ele para muito mais pessoas.
Existem diversos algoritmos sendo o mais comum atualmente as Redes Neurais Artificiais. Essas redes, a grosso modo, são baseadas em pesos numéricos e quanto mais relevante o item, maior peso ele tem.
Concluindo. Deve ser feito um projeto para analisar o problema de negócio e assim planejar a melhor forma de recomendar os itens. Podem ser utilizadas várias abordagens combinadas para conseguir resultados ainda melhores. Todos os dados podem ser analisados e temos um volume cada vez maior. Podemos analisar os dados, por exemplo, das buscas por determinados conteúdos além das tradicionais interações com eles como os clicks, navegação e muito mais.
Por esse post é isso. Espero que você tenha gostado.
Te aguardo em um outro post. Obrigado pela leitura. Valeu!
Alguns Links para saber mais detalhes